
During my internship at Hackernoon, I had a task to fetch some files from GitHub API. Initially, I thought it’d be a simple GET request but soon I realized the work is a headache. The file I needed was quite large and hence the response was telling me to use something different than I already knew. I ended up spending two days on this issue.
Now it’s time to write an article so that my future self and others don’t have to spend so much time on a simple issue.
In this article, I’ll show you how to get files larger than 1MB from the GitHub API. You will learn about the following topics until the end:
- Fetching larger files from GitHub API
- Working with commit’s SHA
- Manipulating blobs and base64 encoded data
For the purpose of this article, I am using data from HackerNoon’s Startup of the Year contest. The data is publicly available on GitHub if you want to follow along.
Get Files Smaller than 1MB
Fetching smaller files is simple and you just need to pass three parameters to the API. First is the owner’s name, which could be your username. The second is repo, which is the name of the repository where your file is committed. And path is the path to the file from the root.
I have created a simple codepen if you want to use working code snippets.
For better understanding, I have created four variables to store data at each state.
let fileSHA, fileBlob, fileContent, file
fileSHAstores the SHA of the file we want to fetch.fileBlobstores the blob fetched from the API.fileContentis used to store the decoded string.filehas the data that we actually need.
You can find the reference code in the next section, just change the folder path with the actual file path (with file extension) and you’re good to go!
The Problem with Large Files
However, if you fetch a file larger than 1MB, the API would throw an error. This is due to the fact that the above endpoint does not support large files. To retrieve the data, we must instead use the Git Database API.
The Git Data API allows you to read and write raw Git objects to and from your Git repository and list, as well as update Git references. This API primarily works with blobs, which is the focus of this article.
Git converts a large file into a base64 encoded blob rather than storing the entire file for better performance. As a result, when you request the same file, it expects you to use the Database endpoint, which returns the blob.
To retrieve a blob, you need to pass file’s SHA. You might ask, what is SHA and how to get it?
Every time you commit a new file, git creates a unique ID called hash or SHA to keep a record of changes. This could cause an issue sometimes but we would discuss this at the end of this article.
Get SHA of the file
For now, we need to figure out a way to get SHA of the desired file. GitHub API has an endpoint to interact with the file content that we can use.
GET /repos/{owner}/{repo}/contents/{path}
In response, we get an array of objects having metadata about every file in the directory. The Metadata contains SHA that we can store and use later.
const getFileSHA = async () => {
try {
const response = await fetch(
"<https://api.github.com/repos/hackernoon/where-startups-trend/contents/2021/>"
);
const data = await response.json();
console.log(data);
fileSHA = data[3].sha
console.log(fileSHA);
} catch (error) {
console.log(error);
}
getFileBlob(fileSHA)
}
data[3].sha has the SHA of votes_by_region.json, so we store it in fileSHA for future uses. The console output would look something like this:
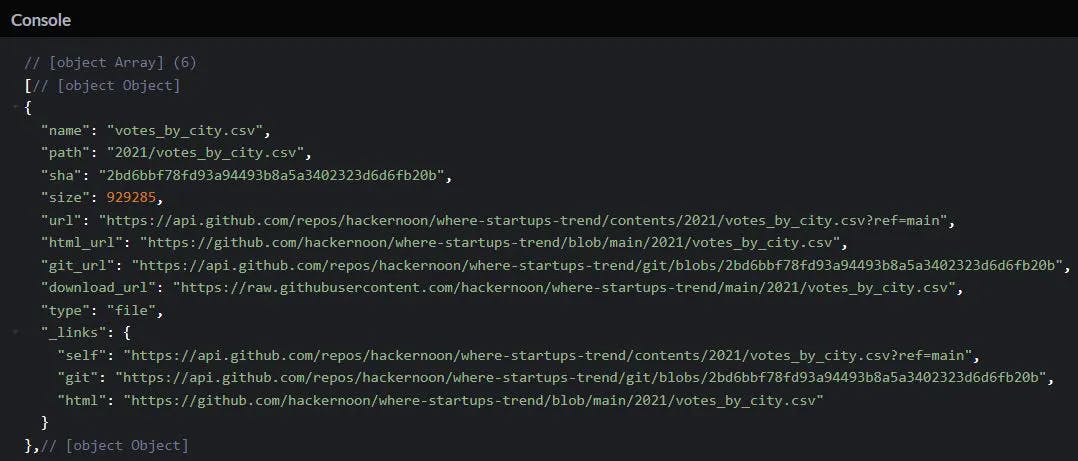
Fetch Blob of the file
We have the file SHA which is required to get the blob. We need to use a different endpoint to work with blobs. This endpoint is similar to the last one but we have to pass file SHA as the third parameter.
GET /repos/{owner}/{repo}/git/blobs/{file_sha}
The following function fetches the blob of our file when we provide its SHA as a parameter.
const getFileBlob = async (fileSHA)=> {
try {
const response = await fetch(
`https://api.github.com/repos/hackernoon/where-startups-trend/git/blobs/${fileSHA}`
);
const data = await response.json();
fileBlob = data.content
convertBlob(fileBlob)
} catch (error) {
console.log(error);
}
}
This request returns a base64 encoded blob. Base64 is an encoding scheme that represents binary data in an ASCII string format. It is useful when we need to store or transfer data without any modification. The console output will look gibberish but it’s just how base64 encoded data is.

Convert Blob into Useful Data
In the final step, we have to convert the base64 encoded blob into something that we can use in our program. This step is quite frustrating because the standard ways don’t seem to work in some cases.
After spending hours on this single problem, I have found three solutions. I don’t guarantee that every solution will work out for you, but I am pretty sure one of them surely will.
Easiest Way
This is the standard way natively supported by JavaScript. atob() is a Web API interface that decodes base64 encoded data into a plain string.
atob is supposed to be read as ASCII to Binary since it converts ASCII encoded base64 data into binary form. The output will be a decoded string. To convert it into its original data type, we use JSON.parse().
fileContents = atob(blob)
file = JSON.parse(fileContents)
Second Way
If the above method throws an error, Node.js provides a method Buffer.from() that you can use. It takes the string to be decoded as the first parameter and the encoding technique as the second.
try {
const fileContents = Buffer.from(fileBlob, "base64").toString()
file = JSON.parse(blobToString)
console.log(file)
} catch(error) {
console.log(error)
}
Third Way
Final Way: There’s a good chance the previous method won’t work if you’re working on the frontend. In such case, create a function that uses decodeURIComponent.
// define the function
const decodeBase64 = str => {
utf8Bytes = decodeURIComponent(str).replace(/%([0-9A-F]{2})/g, function (match, p1) {
return String.fromCharCode('0x' + p1);
});
return atob(utf8Bytes);
}
You can call this function by passing the fileBlob as the parameter, and get your decoded string!
fileContents = decodeBase64(fileBlob)
file = JSON.parse(fileContents)
console.log(file)
Nothing Worked?
Well, there are two final options that you can try. Either you can use FileReader API or use decodeURIComponent in a different way.
FileReader API: You can find MDN docs here. decodeURIComponent: Refer to this blog by Rajeev Singh that handles 16bit encoded strings. Alternatively, you can try an NPM package called js-base64 as well. I have not used it myself so don’t have opinions regarding it.
Restrictions
As mentioned earlier, SHA is the unique ID that changes every time you modify the file. Also, since we have a hardcoded object index in the getFileSHA() function, API might respond with SHA of a different file if you add or delete files in the directory.
To tackle this, you can use the exact file name instead of the index so you can keep the function unmodified after committing new changes.
Summary and TL;DR
- Git stores larger files in blob format and hence we use GitHub Database API to fetch files larger than 1MB.
- We need to provide a username, repo name and the file’s SHA to get the blob.
- To get SHA, we provide a folder path to the endpoint and store it in a variable.
- Later we pass SHA as a parameter to another endpoint and get a base64 encoded blob.
- The blob must be decoded into a plain string and then converted into its original format using
JSON.parse()before you can use it.
More references
Do let me know which decoding method worked for you. I am most active on Twitter, LinkedIn and Showwcase!
Happy fetching!

Kaushal Joshi is a versatile author with expertise in web development and technical writing. With a passion for both coding and effective communication, Kaushal has forged a dynamic career at the intersection of technology and content creation. His proficiency in web development is complemented by a talent for articulating complex technical concepts in clear and accessible language. Through his writing, Kaushal not only contributes to the evolving field of web development but also empowers readers with the knowledge to navigate the digital landscape. His commitment to bridging the gap between technology and understanding makes Kaushal Joshi a respected figure in both the web development and technical writing communities.
Leave a Reply